Figure 4-1. The Waterfall Software Lifecycle Model
| Software Lifecycles |
4.1. What
is Software
Engineering?
4.2. How
is Software Developed -- a Likely
Scenario?
4.3. A
Software Lifecycle
Paradigm
4.3.1.
Concept
Phase
4.3.2.
Definition
Phase
4.3.3.
Development
Phase
4.3.4.
Evaluation
Phase
4.3.5.
Operation
Phase
4.4. The
Waterfall Model vs. the Real
World
4.5. Other
Lifecycle
Models
4.5.1.
Build-and-Fix
Model
4.5.2.
Incremental
Implementation
Model
4.5.3.
Incremental
Development and Delivery
Model
4.5.4.
Prototype
Model
4.5.5.
Spiral
Model
4.6. Lifecycle
Costs
4.7. Software
Characterizations
4.7.1.
What
Makes Software
Different?
4.7.2.
Types
of
Software
4.7.3.
Software
Project Difficulty
4.8.
References
This chapter gives a brief introduction to software engineering. Some of the many definitions and characterizations of software engineering are given. Various paradigms for software development are also presented, concluding with a brief discussion of software lifecycle costs and some general characterizations of software.
A first attempt at a definition of software engineering might be to define software engineering as computer programming. However, describing programming as equivalent to software engineering is the same as saying hardware engineering is just hooking up some integrated circuits. Of course, hardware engineering is much more than this. A hardware engineer must be concerned with precisely defining what is to be built, selecting components to solve the problem, specifying the interfaces among the components and to the outside world, providing documentation and testing, and providing for maintenance of the hardware throughout its lifetime.
One does not just "program some software" any more than one just "hooks up some hardware" for any project of more than a trivial nature. A software engineer is much more than just a programmer. Their concerns are quite different. Turner [Turner 84] describes the concerns of the programmer to include
The concerns of the software engineer include
If software engineering is more than just programming, then what is a good definition of software engineering? There are almost as many definitions of software engineering as there are authors of software engineering texts. At the first major conference on software engineering, Bauer [Naur and Randell 69] gave this definition:
the establishment and use of sound engineering principles in order to obtain economically software that is reliable and works efficiently on real machines.
The key words in this definition are engineering principles, economically, reliable, and efficient.
Turner [Turner 84] defines software engineering as
the practical application of engineering principles and methods in the design, construction, and maintenance of computer programs and the documentation associated with them.
The idea that software engineering involves the maintenance of the software is introduced here. Turner also indicates that software engineering is responsible not only for the computer programs, but also for their associated documentation.
Fairley [Fairley 85] defines it as
the technological and managerial discipline concerned with systematic production and maintenance of software products that are developed and modified on time and within cost estimates.
He adds software management to the equation, along with the thought that production of software should be systematic.
Boehm [Boehm 81] gives this definition.
Software engineering is the application of science and mathematics by which the capabilities of computer equipment are made useful to man via computer programs, procedures, and associated documentation.
Boehm places emphasis on the fact that the issue is not so much to produce software, but rather to make computers provide useful services to people, and that software engineering involves everything necessary to achieve that result.
While not exactly a definition of software engineering, Dijkstra [Dijkstra 89] makes these interesting points about software engineering.
As economics is known as "The Miserable Science," software engineering should be known as "The Doomed Discipline": doomed because it cannot even approach its goal since its goal is self-contradictory ... software engineering has accepted as its charter, "How to program if you cannot."
Finally, Bauer [Bauer 71] made this statement about software engineering at the 1971 IFIP Congress in Yugoslavia:
software engineering is the part of computer science which is too difficult for the computer scientist.
Certainly, while no two of these definitions are the same, a certain theme runs through all of them (with the possible exception of Dijkstra's and Bauer's). Sommerville [Sommerville 92] characterizes these common factors:
. . . software engineering is concerned with software systems built by teams rather than by individuals, uses engineering principles in the development of these systems and includes both technical and non-technical aspects. As well as having a thorough knowledge of computing techniques, software engineers must be able to communicate orally and in writing. They should be aware of the importance of project management and should appreciate the problems that system users may have in interacting with software whose workings they may not understand.
Software does not simply mean the computer programs associated with some application or product. As well as programs, 'software' includes the documentation necessary to install, use, develop and maintain these programs. For large systems, the effort needed to write this documentation is often as great as that required for program development.
But what makes some software well-engineered, and other software not? Sommerville gives four attributes that he believes all well-engineered software possesses. Well-engineered software should
Now that we have an idea of what software engineering and well-engineered software are, let's turn our attention to the software development process.
Consider the following scenario. You are an engineer at a large software company. One day at lunch you meet a friend in Marketing at the same company. She tells you about a "hole" in the product family that is causing the company to lose many sales, and she laments that if the company just had software to fill that need, revenues would increase dramatically.
Being a good software engineer, you quickly finish your lunch and think about the problem all the way back to your office. You get back to the office and immediately start coding the solution. For two months you work very hard and very long hours, spending nights and weekends on the project, not seeing much of your SO 1, and turning down all social engagements. Finally, you have coded the last routine. You take the software over to your friend in Marketing for a demo. As she is exclaiming that this is exactly what was needed, the president of the company walks by and, hearing all the excitement, stops in. When told what happened, the president awards you with a $10,000 bonus, which you immediately take to the local BMW dealer and use for a (small) down payment on a brand new Z3. Meanwhile, your software is taken to manufacturing, placed on the appropriate media, and shipment begins.
Likely? Unfortunately, not very. What's wrong with this scenario? Not that the project idea came from a chance encounter at lunch . . . that happens. Not that you were so enthusiastic about the project that you did little else for two months . . . that happens, too. Not even that you got a big bonus for doing such a great job . . . even that happens. The most unlikely part of this scenario is that you went off by yourself (most interesting and useful projects require more than a single person) for two months and emerged with exactly what Marketing wanted and needed 2, after only a brief discussion of the problem. In addition to the fact that there was no agreement with the customer (in this case, Marketing) as to what exactly the software needed to do, other problems with the scenario are that the software was developed with no thought as to its design, no testing was done before its release, and no user or internal documentation was produced. These are all part of the software engineer's job in the development of real software products.
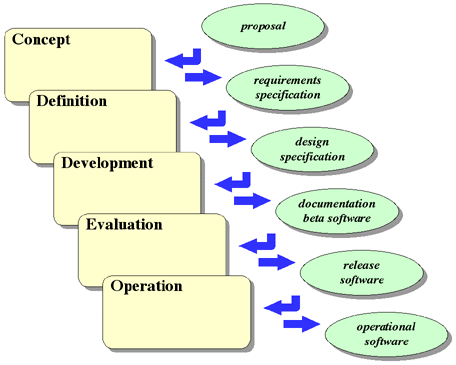
It is convenient to think of a paradigm, or model, for how software evolves
over its lifetime. One model of software evolution is called the Waterfall
Model. This model partitions the development of software into five phases --
the Concept Phase, the Definition Phase, the Development Phase, the Evaluation
Phase, and the Operation Phase. Each phase has a certain set of inputs and a
certain set of activities producing a certain set of outputs, as shown in Figure 4-1.
Each of these phases will be briefly discussed. (This discussion roughly follows
that found in [Turner 84].
Another excellent description of the Waterfall Model may be found in [Ghezzi, Jazayeri, and Mandrioli 91].)
The Concept Phase takes as input a proposal, an idea, or an MRD (Marketing Requirements Document). Through the process of requirements analysis this input is transformed into a set of requirements and a requirements specification. A requirements specification is a document that is meant to describe explicitly what the software is to do from a user's perspective (not how it is to do it). It is essentially a contract between the developer of the software and the person or organization requesting its development.
The Definition Phase takes as input the requirements specification produced during the Concept Phase and, through the process of design, produces a design and a design specification. The design process includes study and research of the problem and trade-off analysis of various solutions as well as the design of the particular solution chosen. The design specification describes how the software is to be implemented, so that it meets the requirements laid out in the requirements specification.
The Development Phase consists of taking the design specification generated during the Definition Phase and, through the development process, realizing that design as code in some language or languages. This includes the detailed design of modules, their implementation as code, and their testing to confirm that they perform as they should. It also includes the integration of the components into a complete system and the testing of the resulting system. The result of the Development Phase is a system ready for beta test, or use by friendly users. The Development Phase also includes a more or less parallel effort to produce the appropriate user and internal documentation.
The Evaluation Phase takes as input the tested software and documentation produced in the Development Phase. This software and documentation are used by relatively friendly users in real situations to further test and evaluate both the software and documentation. These users may be organizations internal to the company or willing users outside the company. Bugs are fixed and modifications are made. The result of this effort is software and documentation ready for general release.
The Operation Phase takes as input the software and documentation produced by the Evaluation Phase. The software is manufactured (placed on the appropriate media), the documentation is printed and packaged, and orders are shipped. Support organizations provide customer support, bugs are fixed, enhancements are made, and new versions of software and documentation are shipped. This phase is repeated throughout the useful lifetime of the software.
The Waterfall Model is only a model, and as such may not always accurately
reflect exactly what happens in real world projects. In practice, the Waterfall
Model is rarely followed by real projects; the life cycle of real software is
much more of an iterative process than that indicated by the model. For example,
during the Definition Phase problems with the existing requirements may be found
or new requirements may arise, causing a return to the Concept Phase for
redefinition of requirements. During the Development Phase, problems may be
discovered in the design or new design ideas may arise, causing a return to the
Definition Phase for modification of the design. Implementation of small
prototypes of the system or of system components are very likely done at various
stages to research requirements, design, and implementation issues. Thus, a more
accurate diagram of the Waterfall Model might include feedback loops to previous
phases. In practice, these feedback loops may not only go from one phase to the
preceding phase, but perhaps to any previous phase as well. A more realistic
version of the Waterfall Model is shown in Figure 4-2.

Another problem with the Waterfall Model is that, if followed explicitly, a working program comes very late in the project -- after a significant portion of the development time has been spent gathering requirements and writing a requirements specification, designing the system and writing a design specification, and implementing and testing the individual software components. This is generally much too far into the development process to get the first glimpse of what the working software will look like, and in general, much too late to correct major requirements or design problems without severely impacting the product schedule.
A more realistic and practical approach that complements the iterative nature of real software development is the development of many prototypes of various system components or of the system as a whole along the way towards the "final" implementation. At each phase of development, prototypes are built to help solidify the issues pertinent to that phase. For example, prototypes may be constructed to help determine what the requirements should be, to assist in verifying the appropriateness of the design, or to investigate implementation issues such as performance. This "rapid prototyping" not only helps to discover problems as early as possible, but it also results in a more interesting and exciting development process in that the project team can more readily see results and progress along the way.
Although the Waterfall Model may not accurately reflect the life cycle of all (or any) real software development exactly, it is a good first approximation. All projects, large and small, formally-developed and informally-developed, go through essentially the same five phases. Certainly these phases take on many different forms depending on the project, the company, and the individuals involved. Also, the exact nature of the iteration and feedback among phases may vary. But they all involve the following issues:
There are many other software lifecycle paradigms, each with its own advantages and disadvantages. Several of these models -- Build-and-Fix, Incremental Implementation, Incremental Development and Delivery, Prototype, and Spiral -- are described briefly below. These paradigms, along with others, are described in more detail in [Ghezzi, Jazayeri, and Mandrioli 91], [Pressman 92], and [Schach 90].
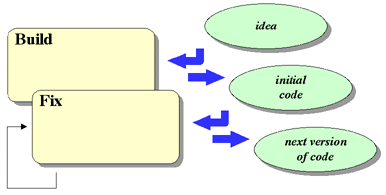
The Build-and-Fix Model is essentially the model used in the development of
the earliest computer programs. No requirements are specified and no real design
is done. An initial product is built, and it is repeatedly modified until it
satisfies the customer, as shown in Figure 4-3.
Unfortunately, the lack of real requirements and design, along with repeated
modification of the code, results in a system that deteriorates rapidly. This
model is practical only for very small, single-person, user-developed projects.
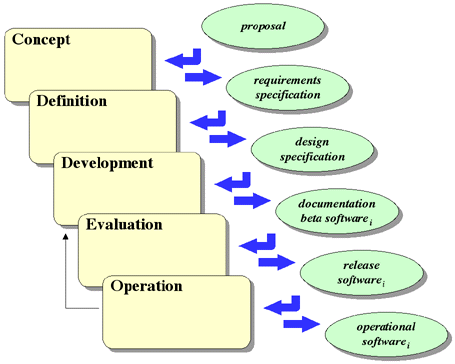
The Incremental Implementation Model is based on a slight modification of the
Waterfall Model. The Waterfall Model completes each step of the process for the
entire software system. The Incremental Implementation Model follows the
Waterfall Model through design. During implementation the project is decomposed
into useful subsets (which were identified during requirements analysis and
design) that are then implemented separately, as shown in Figure 4-4.
This approach simplifies the development of the software to some extent, since
the implementations of the smaller increments should be easier than the
implementation of the entire system at once.
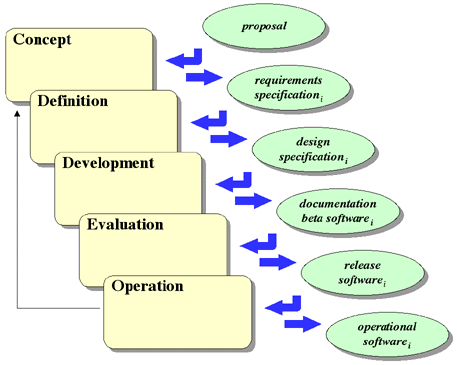
The Incremental Development and Delivery Model extends the incremental
implementation idea to encompass the entire software lifecycle. Useful
increments are identified at the beginning of the development process, and the
entire process from the generation of requirements to delivery of the product is
carried out for each increment, as shown in Figure 4-5.
This approach has the advantage that the development of each increment is
simpler than that of the whole. In addition, each iteration through the loop
provides more feedback from the customer that can be used to refine the
requirements and to improve the product, and the developers should benefit from
increasing understanding of the development environment and of the product
itself.
In the Prototype Model, any known initial requirements are gathered from the
customer. A quick design based on these requirements is done, followed by the
rapid implementation of the prototype. The customer then evaluates this
prototype. At this stage, if enough is not known to begin development of the
actual product, further iterations through the prototype lifecycle can be made
to refine the requirements and further develop the prototype. Once enough is
known to begin development of the actual product, the prototype is thrown away
and the product is engineered following any appropriate model, as shown in Figure 4-6.
This model is very useful when the customer has only a vague understanding of
the requirements, and also when the developers are unfamiliar with the
development environment.
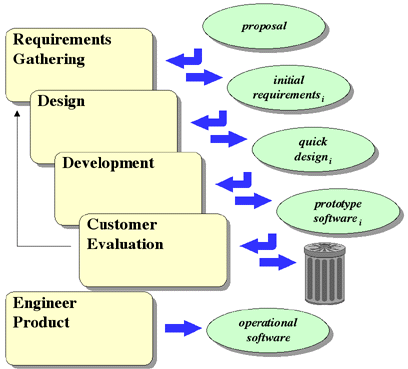
The Spiral Model combines some aspects of the Prototype Model and the
Waterfall Model into a cyclic model consisting of four stages: Planning, Risk
Analysis, Engineering, and Customer Evaluation, as shown in Figure 4-7
(based on [Pressman 92]).
The model begins in the Planning stage with the initial gathering of
requirements. Then the project enters Risk Analysis to determine if there are
any conditions that might adversely affect the project, after which a decision
is made to continue or abandon the project. If the decision is made to continue,
the project enters the Engineering stage, where an initial prototype is built.
The prototype is then given to the customer for evaluation and feedback in the
Customer Evaluation stage, after which the project returns to Planning. Based on
the initial prototype and customer feedback, new requirements are generated, and
the project continues through the spiral. After each loop through the spiral a
more complete system is produced, eventually resulting in a finished product.
Often the lifecycle cost of software is thought of in terms of the cost of
development -- the engineers, hardware, and other resources required to
introduce the product. However, it has been estimated that from 50% to 75% of
the lifecycle cost of software is in maintenance, occurring during the Operation
phase of the product's lifecycle [Boehm 81].
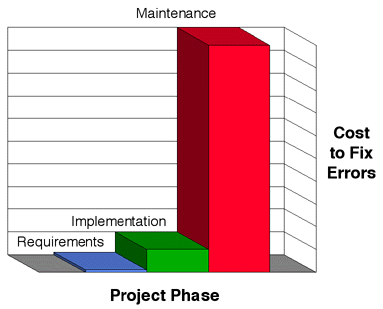
It is also interesting to note results of research on the cost to fix problems
in the various stages of the lifecycle, as shown in Figure 4-8.
Software requirements errors detected and fixed during requirements analysis are
usually simple and inexpensive to fix. However, if that same error is not
detected until implementation, it will typically cost an order of magnitude more
to fix. And if it is not detected until maintenance (during the Operation
phase), it will typically cost two orders of magnitude more to fix [Schach-90].
Given these numbers, it is easy to understand why a significant part of software
engineering is devoted to the early detection of problems (in requirements,
design, and implementation), and to the development of software that is
highly-maintainable.
Software can be characterized in many ways, several of which are described below. These characterizations include how software development differs from other types of development, a description of some of the various broad categories of software, and a brief discussion of the determining factors in the degree of difficulty of a software project.
Many types of systems are developed using approaches seemingly similar to that of software. An idea is formulated, requirements are developed and converted to designs, and the system is implemented and put into use. These systems include computer hardware, appliances, automobiles, buildings, bridges, and many, many others. Why does software have issues that make its development different than that of many other systems? Pressman [Pressman 92] gives several characteristics of software that make its development different from that of hardware systems:
- Software is developed or engineered, it is not manufactured in the classical sense.
- Much of the cost and difficulty of the development of a hardware system lies in its manufacturing and associated quality control. In software development, manufacturing is simplified, while much of the cost and complexity is concentrated in the engineering of the product. Software projects cannot be managed as if they were manufacturing projects.
- Software doesn't "wear out".
- Hardware systems tend to exhibit relatively high failure rates initially, but tend to stabilize over time as design and manufacturing defects are corrected. Failure rates then tend to rise again toward the end of the product's life as components wear out from use and environmental effects. The useful life of the hardware can be extended by the replacement of worn-out components. Software exhibits similar higher failure rates initially, with failures tending to be reduced as initial problems are corrected. However, during the course of maintenance, as more and more bugs are repaired and enhancements are made, the software tends to deteriorate due to the increasing amount of change it has undergone. Software "spare parts" cannot be used to extend the useful life of the software product.
- Most software is custom-built, rather than being assembled from existing components.
- Hardware systems are typically built using standard, validated components with well-defined interfaces which can be integrated according to established guidelines. While the trend in software is towards the reuse of software components in a similar manner, the software industry is still a long way from the level of reuse available to the hardware industry.
Ghezzi, Jazayeri, and Mandrioli [Ghezzi, Jazayeri, and Mandrioli 91] indicate two additional characteristics that tend to distinguish software development from production and manufacturing activities:
- Software production is a largely intellectual activity.
- Manufacturing is typically a very repetitive, mechanical process, for which automation is very practical and appropriate. Due to the relatively high level of intellectual activity required in software production, it is not very amenable to automation.
- Software production is characterized by a high degree of instability.
- Requirements change frequently, necessitating frequent changes in the software designs and implementations.
In the early days of computing, software and computers were primarily used for computation. As the industry continues to expand, software is used in a wider and wider variety of problem domains. Pressman [Pressman 92] lists seven different areas of software application:
- System
- provides services needed by other software. These include compilers, editors, and operating systems.
- Real-Time
- monitors, analyzes, and controls real world events, requiring responses within strict time constraints. These include the control of manufacturing processes, aircraft and weapons control, and high-speed data acquisition.
- Business
- facilitates business operation and decision making. These include payroll, accounts receivable, personnel, and point-of-sale systems.
- Engineering/Scientific
- provides aides to engineering processes and scientific research. These include numeric computation, computer aided design, and data visualization.
- Embedded
- resides within and controls systems in the commercial, industrial, and military markets. These include control of the operation of appliances, industrial machines, and weapons systems.
- Personal Computer
- provides useful tools for users of personal computers. These include spreadsheets, databases, and word processors.
- Artificial Intelligence
- solves complex problems intractable to conventional software. These include expert systems, pattern recognition, and neural networks.
These different problem domains often have differing software engineering issues.
Estimating the difficulty of a software project is in itself a difficult
task. If the level of difficulty of a project is not very well understood, it
becomes hard to do reasonable project planning. While there have been many
attempts to measure software difficulty by various metrics (e.g. estimating the
number of lines of code or number of functions required to implement the
software), they have often been of marginal use. One of the better measures is
presented by Pfleeger [Pfleeger 91].
Pfleeger's method examines a number of characteristics of the software and
assigns one of three levels of difficulty (Low, Moderate, or High) to each
characteristic, as shown in Table 4-1
below.
| Characteristic | Low | Moderate | High |
|---|---|---|---|
| Number of functions performed | Small | Medium | Large |
| Novelty of function | Standard application | Similar to existing systems but with a few new functions | New theory or approach; never been built before |
| Number of users requiring multi-user or concurrent access | 1 | Several | Many |
| Multi-tasking | No | Some | Yes |
| Interactive vs. batch access | Batch or some minimal interaction | Highly interactive | Highly interactive |
| Response time requirements | Off-line; noncritical | Interactive; moderate response time acceptable | Real-time |
| Need for distributed processing | None | 2 computers | 3 or more computers |
| Amount of data stored | Will fit on a single disk (storage device) | Requires 2 or more disks | Requires system to manage disk access |
| Structure of data | Simple data relationships | Moderately complex relationships | Highly complex relationships |
| Accuracy of data | Low degree | Moderate degree | High degree |
| Transaction size | Small | Medium | Large |
| Remote vs. local | Local only | Remote | Remote access |
| Criticality; tolerance for downtime | Can tolerate several hours of downtime | Can tolerate short periods of downtime | Can tolerate no downtime |
| Security needs | None | Moderate | High |
| Interaction with other systems | None | Some but well defined | Much; possible parallel development |
| Number of phases of development | None | Few | Many |
| Need for manual override | No | No | Yes |
| Dependence on hardware | Independent of hardware | Some | Tied to specific hardware constraints |
| Stability of specification | Fixed customer requirements | Some changes may occur | Frequent changes in specification |
| User sophistication | Familiarity with automated systems | Some familiarity with automated systems | Naive |
| Developer sophistication | Has developed similar systems with similar tools | Experience with tools, not with application | No experience |
The results can then be examined to determine if the project generally falls into the category of Low, Moderate, or High difficulty. While not nearly as quantitative as estimating lines of code, this method provides a better general estimate of the difficulty of a project.
1 significant other.
2 It should be emphasized that what Marketing wants and what Marketing needs are not necessarily the same thing. Determining what Marketing needs given what Marketing wants is yet another way in which a software engineer's job differs from that of a programmer.
3 A slightly more humorous model of software development describes the six phases of a software development project as
While this model unfortunately often has some hints of truth in it, it is exactly this sort of situation that good software development practices are attempting to avoid.